Why Context Matters for Enterprise Productivity
In the enterprise, AI agents promise transformative productivity gains — automating financial modeling, generating board-ready presentations, drafting strategic memos, orchestrating multi-team workflows, and even conducting competitive intelligence analysis. But there's a catch: these impressive capabilities mean nothing without the right context.
Consider a CFO asking an agent to “prepare our Q4 budget variance analysis.” To deliver a meaningful response, the agent needs to pull information from dozens of sources: last quarter's actuals buried in articles and meeting recordings, strategic priorities mentioned in the CEO's slide deck, departmental requests scattered across email threads, and year-over-year comparisons from PDF financial reports. Without access to these contextual puzzle pieces, even the most sophisticated AI agent is reduced to generic advice.
At Synvo AI, we believe corporate file systems are the richest riverbed for mining business context. Files are where organizational knowledge lives — not in neat databases, but in the messy, multimodal reality of how people actually work.
The Chaos of Real-World Information
Real-world business information doesn't arrive in clean, structured formats. It's scattered across PDFs, images, screenshots, presentations, email attachments, and video recordings. A single strategic decision might require synthesizing insights from:
- Market research in PDF reports
- Customer feedback in email screenshots
- Competitive analysis in PowerPoint decks
- Product roadmaps in Figma exports
- Meeting discussions on video transcripts
To build AI agents that can truly help, we needed to train and test them in an environment that reflects this reality. That's why we created the Chaos Sandbox — a realistic computer environment designed to mirror the multimodal complexity of actual business workflows.
Building the File System: A Prototype Grounded in Reality
Our philosophy was simple: don't clean up the mess — embrace it. Rather than creating idealized test datasets, we constructed a sandbox that captures the authentic diversity of corporate information.
Imagine a product manager's file system the week before a major launch: quarterly OKR documents, competitor analysis PDFs, screenshots of user feedback from Slack, video recordings of customer interviews, email threads with engineering leads, and presentation drafts for the executive review. Information flows across formats, timestamps, and contexts — no single file tells the complete story.
This research informed our file system prototype — a realistic sandbox containing 100 carefully curated files that matches real-world scenarios with the following distribution:
- 46% PDFs (.pdf) — reports, contracts, research papers, financial statements
- 46% Images (.jpg, .png, .jpeg) — screenshots, diagrams, charts, infographics
- 2% Word documents (.docx) — memos, drafts, meeting notes
- 1% Presentations (.pptx) — pitch decks, strategy reviews, training materials
- 1% Video files (.mkv) — recorded meetings, demos, presentations
This distribution mirrors real-world usage patterns, where visual and document content dominates enterprise file systems.
Real-World Use Cases: What Corporate Agents Actually Need to Answer
To validate our contextual intelligence architecture, we started by building a proof-of-concept system that demonstrates core capabilities across diverse file types and query patterns. Our current 100-file benchmark tests fundamental retrieval challenges:
- Cross-file information synthesis — connecting data scattered across multiple files
- Multimodal understanding — understanding text, images, charts, and videos together
- Temporal and relational queries — finding information based on time, location, or relationships
- Provenance and auditability — providing exact references to source documents for verification and compliance
These capabilities form the foundation for enterprise applications. The same architecture that retrieves information from diverse file systems can be scaled and specialized for business contexts such as the following scenarios:
Financial Analysis & Reporting
Example query: “Will Company A consider slowing down its buyback pace as cash reserves decrease or the interest rate environment changes?”
To answer this, an agent must synthesize information from multiple sources: quarterly earnings call transcripts discussing capital allocation strategy, balance sheet data from financial statement PDFs, strategic commentary in investor presentation slides, cash flow projections from internal analyst memos, and interest rate sensitivity analysis from treasury reports. The answer isn't in any single document — it emerges from understanding how these pieces connect.
Strategic Planning & Execution
Example query: “Create a detailed work schedule and resource allocation for the Q4 product launch based on past sprint velocity and current team capacity.”
This requires integrating project management data from tracking tools, team calendars showing availability, historical performance reports documenting past sprint velocities, current resource utilization dashboards, and dependency maps from technical specifications. The agent must understand not just what's written, but the relationships between team capacity, historical patterns, and upcoming commitments.
Compliance & Due Diligence
Example query: “Extract all mentions of data privacy commitments from our vendor contracts signed in 2024 and verify against GDPR requirements.”
The agent must parse dozens of contract PDFs with varying formats, cross-reference specific clauses against GDPR regulatory documents, identify potential compliance gaps, and flag contracts requiring amendment. This demands precise extraction, legal reasoning, and the ability to trace every claim back to source documents for audit purposes.
Competitive Intelligence
Example query: “Compare our Southeast Asia market positioning against competitors based on internal sales data, market research reports, and customer feedback.”
This synthesis task requires triangulating internal Excel sales dashboards, external market research PDFs from firms like Gartner and Forrester, email threads containing customer feedback, CRM data exports, competitive analysis presentations, and news articles about competitor moves. The agent must understand which sources are authoritative for which claims and how to weight conflicting information.
Benchmarking Against the Competition: How Synvo AI Stacks Up
Building a contextual intelligence system is one thing — proving it works in the real world is another. To validate our approach, we conducted comprehensive benchmarking tests comparing Synvo AI against leading competitors in the file understanding and retrieval space.
The Competitive Landscape: Two Categories of Solutions
When evaluating contextual search and file understanding, we identified two distinct categories of competitors:
- Category 1: Major Platform Solutions — OpenAI Projects, Google NotebookLM, Claude Projects
- Category 2: Specialized Retrieval Tools — Supermemory, Ragie AI, CustomGPT
Each category has different strengths and trade-offs. Major platforms offer polished user experiences but with significant limitations. Specialized tools focus on intelligent retrieval but often struggle with multimodal complexity and scale.
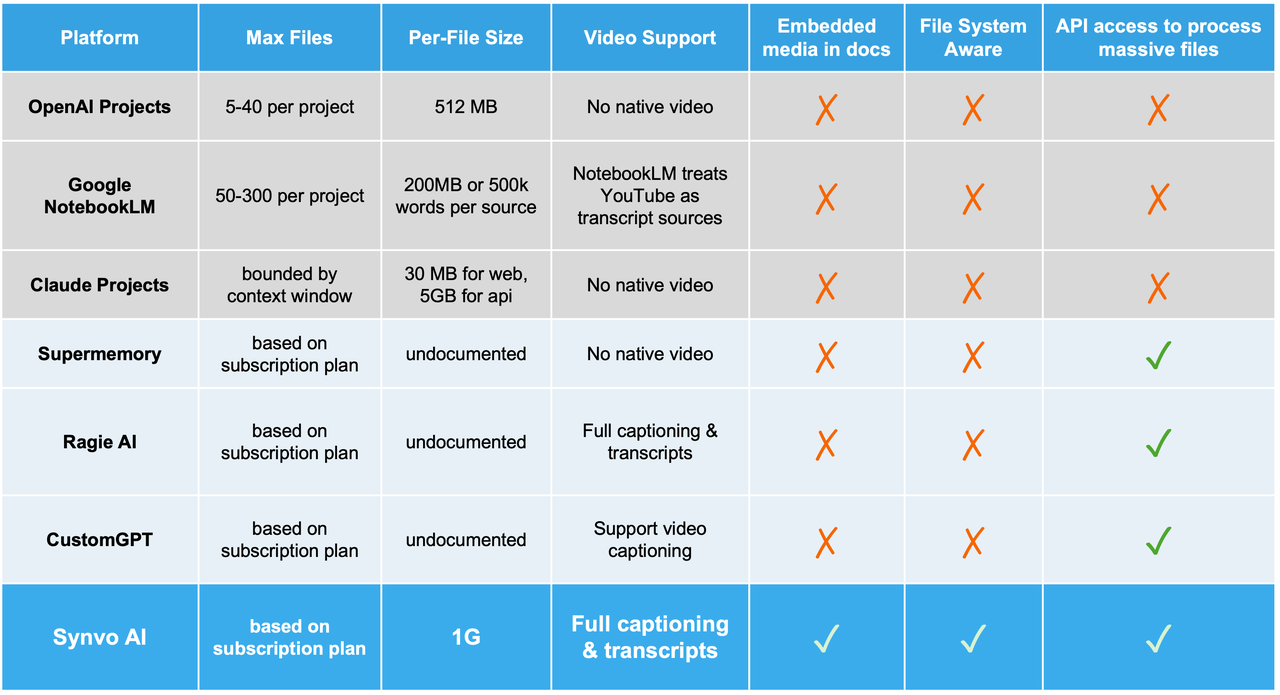
Feature Comparison: A Comprehensive View
Before diving into performance numbers, it's critical to examine the fundamental capabilities across all platforms. We evaluated how each system handles large files, embedded media, multimodal content, and cross-file reasoning.
Key Observations
- Partial processing of large files — Most platforms struggle with very large documents. A 200-page technical specification or 2-hour conference call recording often gets truncated, losing critical information buried in later sections. This isn't just a minor inconvenience — in enterprise contexts, the most important details are often in appendices, fine print, or extended discussions.
- Embedded media blindness — None of the major platforms or specialized tools properly handle embedded media within documents. The chart in a quarterly report, the diagram in a technical spec, and the screenshot in a project proposal often contain more signal than surrounding text, yet they're largely ignored or poorly understood.
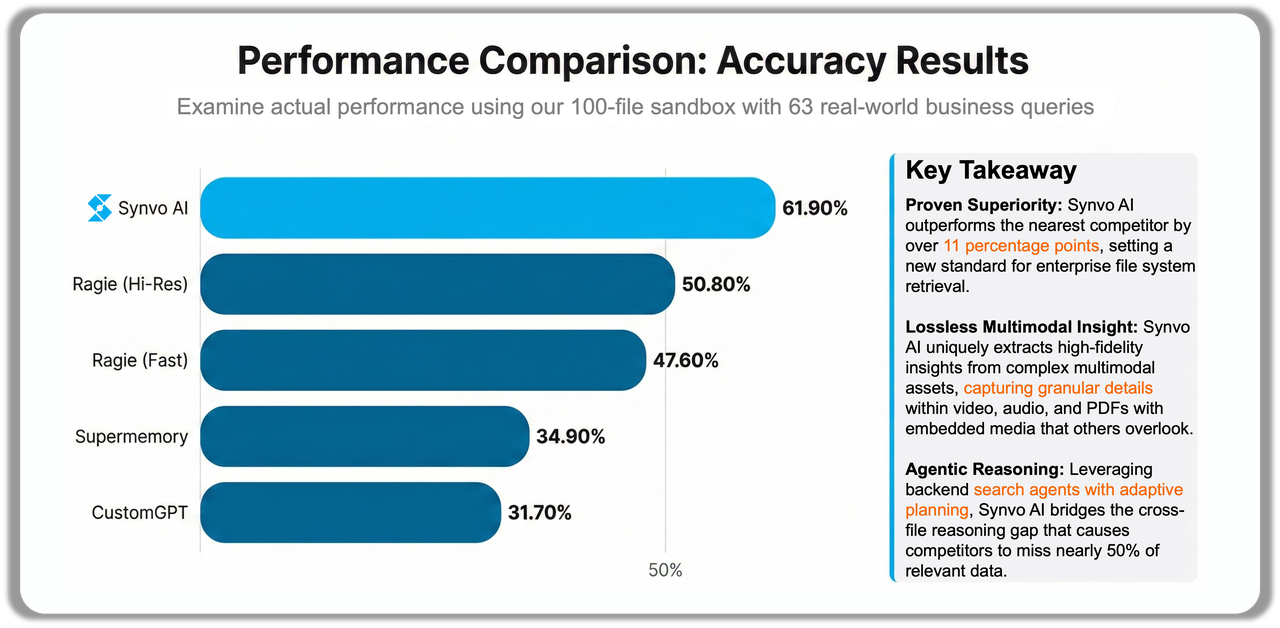
Performance Comparison
With feature differences established, we evaluated actual performance. Using our carefully constructed 100-file sandbox with 63 real-world business queries, we measured how each system performed on realistic tasks spanning multiple modalities and file formats.
The gap is substantial. Synvo AI achieves nearly double the accuracy of most competitors when handling real-world queries across diverse file types. This isn't just about better embeddings — it reflects our system's ability to understand context, reason across modalities, and connect information scattered across multiple documents.
Following recent practice in large-scale generative model evaluation, we adopt a stronger LLM as an automatic judge to assess answer correctness. We use GPT-4o (2025-01-01-preview) to evaluate model outputs by comparing the generated response with the ground-truth answer given the original query. The judge is instructed to focus on semantic correctness and contextual relevance, allowing for valid paraphrases and synonymous expressions rather than exact string matches.
For each query, GPT-4o returns (i) a binary correctness decision (yes/no) and (ii) an integer score from 0 to 5, indicating the degree of meaningful alignment between the prediction and the reference answer. We report accuracy, average score, and average response time, aggregated across all evaluation samples.
Scaling Up: The 500-File Challenge
Small-scale demos are easy. The real test comes at scale. To validate that our architecture maintains performance as file systems grow, we conducted preliminary testing with 500 files and 128 questions — more than doubling both dataset size and query complexity.
Scaling introduces multiple challenges:
- Increased noise — more irrelevant documents to filter through
- Harder retrieval — finding needles in larger haystacks
- Complex cross-referencing — queries requiring information synthesis across 5+ documents
Despite these challenges, Synvo AI maintains 48.8% accuracy on the 500-file scale. While this represents an expected difficulty increase (more files mean harder retrieval problems), it validates that our architectural approach remains robust as corporate file systems grow.
What Makes Synvo AI Different?
Our competitive advantage comes from three architectural pillars:
- Deep multimodal understanding — We don't just extract text from PDFs or OCR images — we process images, videos, audios, and documents thoroughly, understanding the semantic relationships between visual elements, textual content, and embedded media.
- Precision-engineered embedding pipeline — We treat embedding quality as a first-class engineering challenge. Our multimodal models are customized to generate outputs specifically designed for semantic chunking — ensuring each embedded unit represents a coherent multimodal concept, so when our retrieval system finds a relevant passage, it's genuinely relevant, not contaminated with unrelated context.
- Contextual reasoning through agentic exploration — Our system employs an agentic pipeline that explores file systems iteratively — examining initial results, formulating follow-up searches, resolving cross-references, and synthesizing coherent answers from multiple sources. Rather than returning results from a single query, our approach allows the system to refine its search strategy based on discoveries, navigating intelligently like a human analyst.
Looking Ahead: Beta Testing and Open-Source Release
Synvo AI's contextual intelligence system is currently in beta testing, refining performance on real-world file systems containing thousands of documents. For developers and researchers, you can explore our detailed documentation at Synvo AI Docs.
Next month, we're open-sourcing our benchmark and evaluation pipeline — allowing the community to reproduce our results, test competing approaches, and push the boundaries of contextual intelligence.
Conclusion: Context is Everything
At Synvo AI, we’re developing the contextual memory layer that next-generation AI agents need to deliver real value in enterprise environments. Our benchmarking results reaffirm a core belief: accuracy at scale, multimodal understanding, and contextual reasoning are not merely optional features — they are the bedrock of AI systems that truly enhance human work.
The future of work isn’t just about AI that can think — it’s about AI that can remember, connect, and fully understand the context of how businesses operate.
Our technology is already being applied to video asset processing and analytics, with opportunities being explored in large enterprises. We're deeply focused on B2B solutions and are open to business discussions to expand these opportunities.